1. Introduction
2. History and Overview about Artificial Neural Network
3. Single neural network
7. References
2. History and Overview about Artificial Neural Network
3. Single neural network
- 3.1 Perceptron
- 3.1.1 The Unit Step function
- 3.1.2 The Perceptron rules
- 3.1.3 The bias term
- 3.1.4 Implement Perceptron in Python
- 3.2 Adaptive Linear Neurons
- 3.2.1 Gradient Descent rule (Delta rule)
- 3.2.2 Learning rate in Gradient Descent
- 3.2.3 Implement Adaline in Python to classify Iris data
- 3.2.4 Learning via types of Gradient Descent
- 3.3 Problems with Perceptron (AI Winter)
- 4.1 Overview about Multi-layer Neural Network
- 4.2 Forward Propagation
- 4.3 Cost function
- 4.4 Backpropagation
- 4.5 Implement simple Multi-layer Neural Network to solve the problem of Perceptron
- 4.6 Some optional techniques for Multi-layer Neural Network Optimization
- 4.6.1 Adaptive Learning Rate (Annealing)
- 4.6.2 Momentum Terms
- 4.6.3 Regularization
- 4.7 Multi-layer Neural Network for binary/multi classification
- 5.1 Overview about MNIST data
- 5.2 Implement Multi-layer Neural Network
- 5.3 Debugging Neural Network with Gradient Descent Checking
7. References
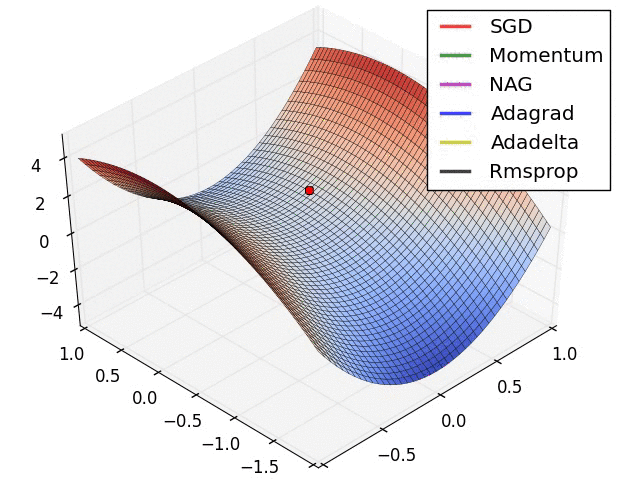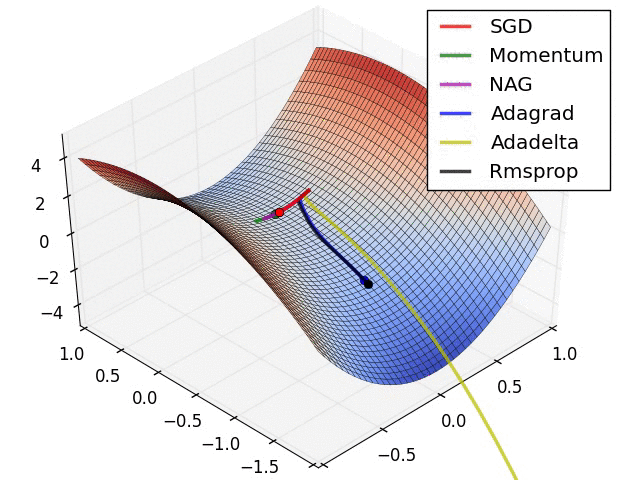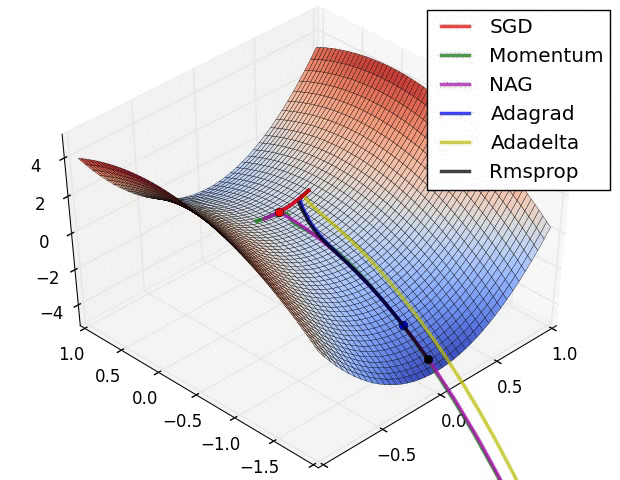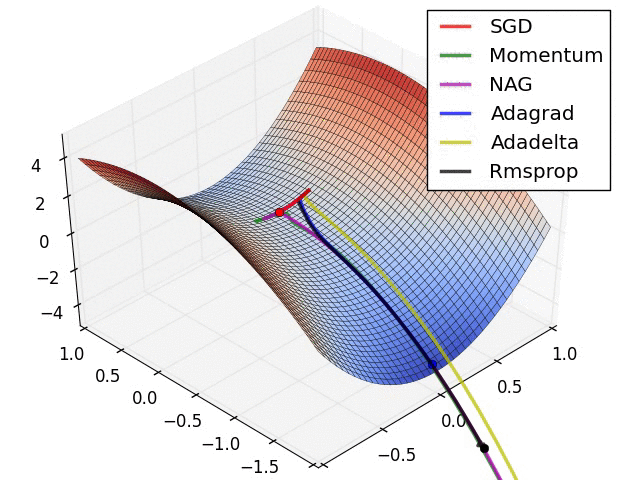
Momentum Terms
Momentum (\(\alpha\)) is very useful when we apply Multi-layer Neural Network in the real world with some problems such as trapped in local minima, slow training or in the case of Stochastic Gradient Descent where the gradient can oscillate too much, then Momentum came to save us. In fact, Momentum came from physics that describes the particle is moving then suddenly it stop cause the inertia.So, let's define Momentum term in the case of Neural Network. It's an extra value with range from \(0.0\) to \(1.0\) to determine how much previous \(\Delta W_{(t - 1)}\) is contributed to current \(\Delta W_{(t)}\) with the formula,
\(\Delta W_{(t)} = \Delta W_{(t)} + \alpha\Delta W_{(t - 1)}\)
Where,
- \(\alpha\) is the Momentum value with \(0 < \alpha < 1\)
- \(\Delta W_{(t)}\) is the current weight update
- \(\Delta W_{(t - 1)}\) is the previous weight update
- \(t\) is current time and \(t - 1\) is the previous time
When training Neural Network in the real world with a large dataset, it's bad if we use Batch-Gradient Descent, instead, we can use Stochastic Gradient Descent. But with Stochastic Gradient Descent, the gradient oscillate too much at the initialization, then the Momentum \(\alpha\) came to smoothing out the variation when the learning rate \(\eta\) can not do that or maybe can do but very slow.

No comments :
Post a Comment
Leave a Comment...